Hello!
I’m experiencing some issues with (even simple) XLIFF 1.2 files that hopefully someone can help with please.
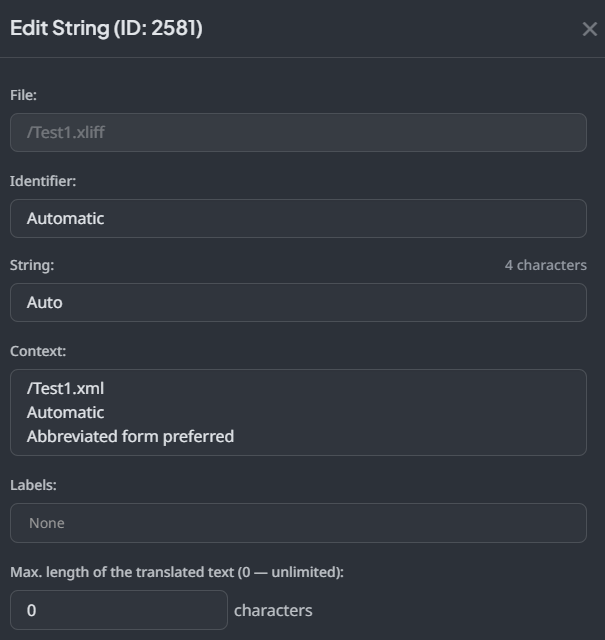
The following XLIFF 1.2 test file is imported into my project with the following unit defined…
<trans-unit id="Automatic" resname="Automatic">
<source>Auto</source>
<target state="needs-translation">Auto</target>
<context context-type="context">Abbreviated form preferred</context>
</trans-unit>
But this results in the following in the editor…
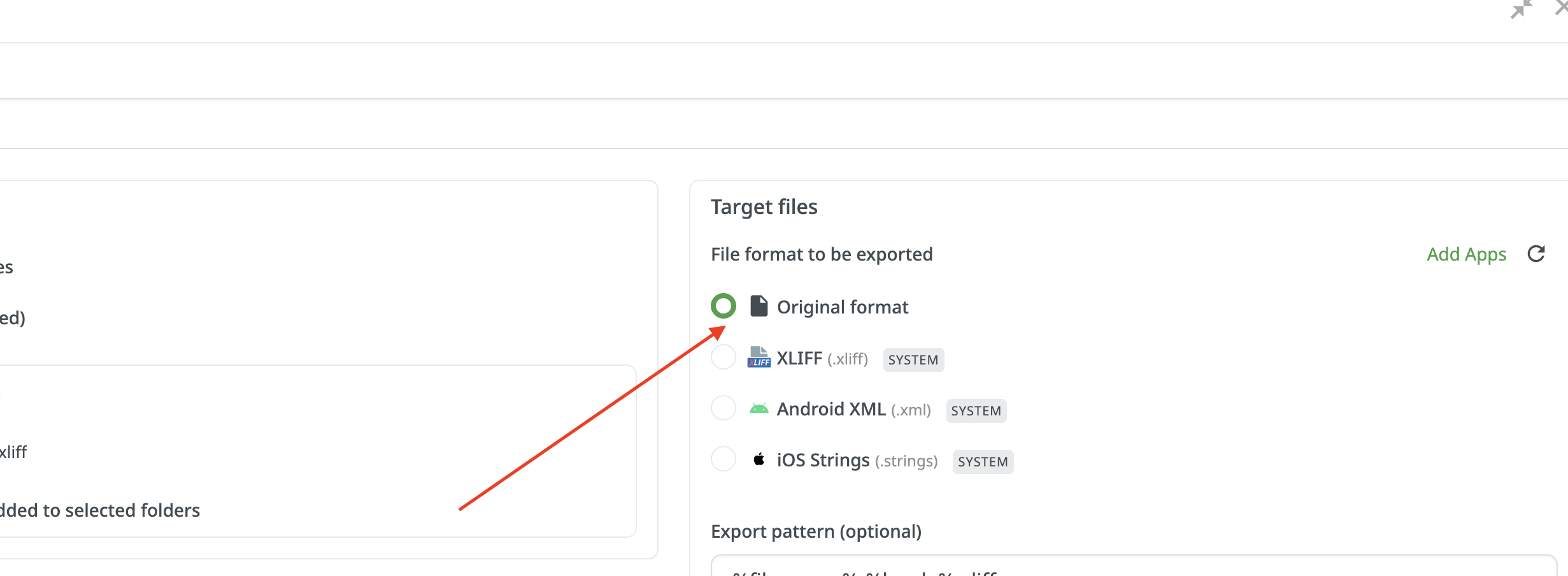
And when the file is exported as part of a bundle, the unit in the file now looks like this…
<trans-unit id="2581" resname="Automatic">
<source>Auto</source>
<target state="needs-translation">Auto</target>
<context-group purpose="information">
<context context-type="source">/Test1.xmlAutomaticAbbreviated form preferred</context>
</context-group>
</trans-unit>
NOTE: It also exported the context with line breaks, which had to be removed for inclusion here.
So my questions are…
- Why has my own id been overwritten with a numeric one?
- Why has extra unnecessary information been added to the context?
- Why has the file format not been preserved (in that a context-group element has been added)
Any help would be much appreciated.
Kind regards, David