We have been using crowdin + in-context in our development environment for a few months now. And everything has been awesome.
We use gitflow as our branch strategy so we have a main branch for production, develop and feature branches for development, and a release branches for testing. The main branch reflects what’s in the latest version deployed to production. The develop branch reflects the base branch for all feature branches and is the target for all feature pull requests. Our release branches are based on develop. We will cut a release branch when we are about to release, perform testing, fix bugs, and then merge that branch to the main branch when regression testing is completed.
We recently cut a new release branch in order to finalize our latest release. We continuously deploy the release branch to our staging environment and wanted translators to continue fixing translations during testing.
After reading and re-reading the Versions Management documentation
… we added the release branch to our Crowdin project
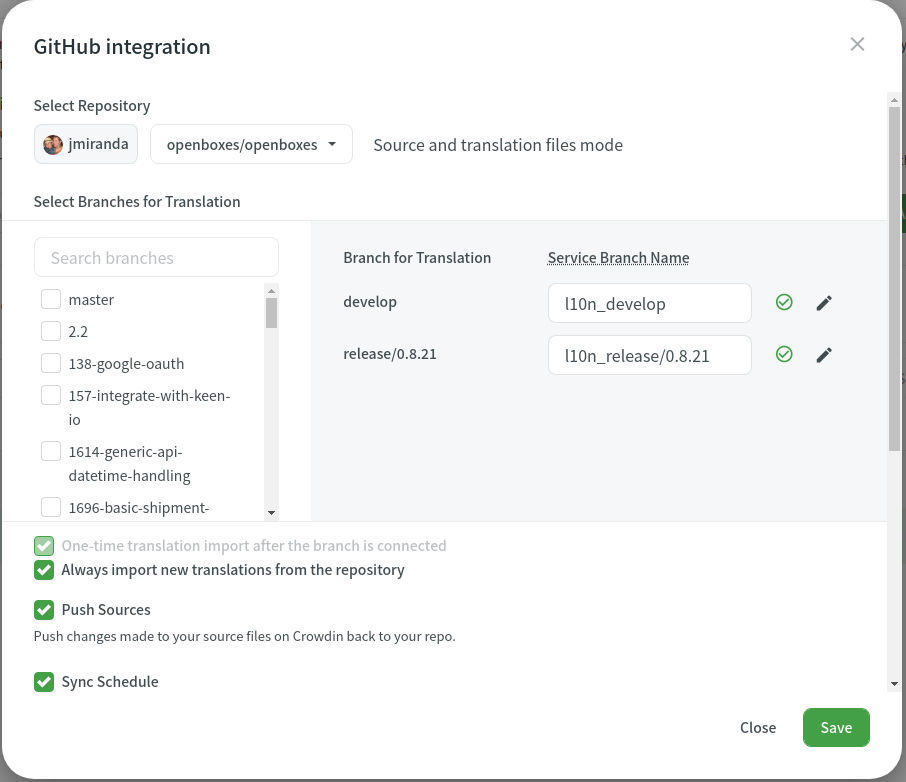
and selected the “Show within a version branch (strict detection)”

based on the recommendation from the above documentation.
Because branches are different versions of the same product feature, their localization content is usually duplicated. To help translators translate versions consistently and avoid additional translation costs, we have the Show within a version branch option that allows hiding duplicated strings only between versions. If your source files contain strings with apparent identifiers (keys), it’s better to use a strict version of this option. In other cases, feel free to use a regular one.
When this option is chosen, only the master strings first uploaded to the system should be translated. All duplicated strings will automatically gain translations from the master strings.
However, this does not appear to be working as I expected.
What we expected was for the release branch to share the same source file (master strings) as develop and allow users to continue translating for the release. When done we’d just merge the release branch into the main branch and develop and everything would be sync’d up.
What we got was a new PR from the service branch to our release branch with all new master strings. New Crowdin updates by jmiranda · Pull Request #3777 · openboxes/openboxes · GitHub
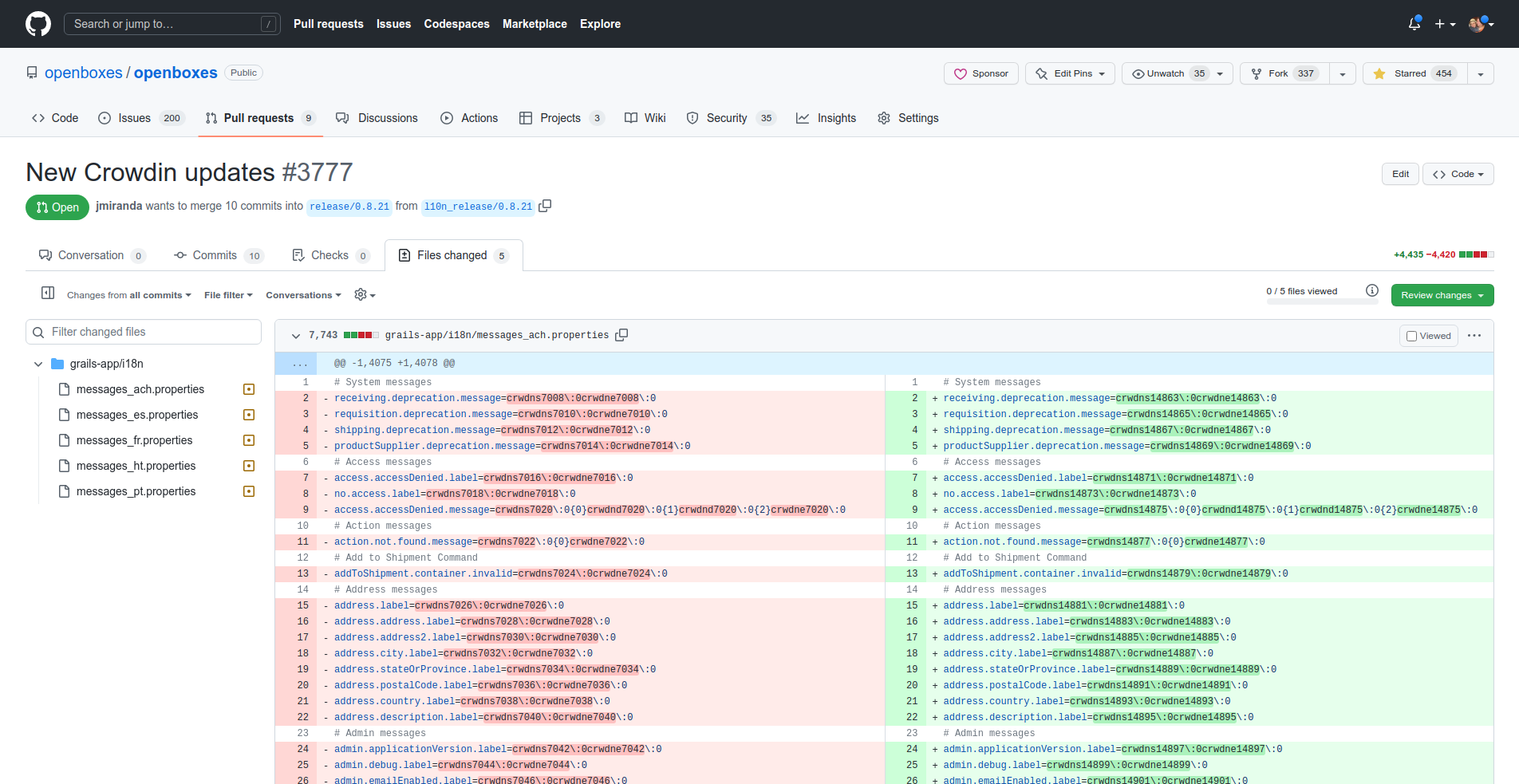
So I’m curious what I did wrong with the configuration to get here and what I can do to fix it.
Thank you in advance.
Justin