Hi, I wanted to pre-translate a text with an AI model that I fine-tuned, but I noticed that the AI only automatically confirms translations that are a 100% match from the translation memory, it shows matches below 100% in the “Suggestions” section. I was wondering if there is a feature that allows adding even a single matching word from the translation memory to the pre-translate. Let’s say 30% of a sentence matches, can AI automatically approve that 30% but not touch the rest?
If there is such an adjustment, how can I do it ?
Hi, @egmnshnky!
The AI takes the TM settings that are set in the project settings.
Unfortunately, it is not possible to allow approval for matches less than 100%.
You can try to enable auto-substitution which can help translations to level up their percentage. However, it doesn’t guarantee that those translations will upgrade to 100%.
Then, if this is the case, why there is need to fine-tune AI? I mean could pre-translate with only translation memory.
Since both of them only approves %100 matches.
The fine-tuning feature is created to provide your entire TM or termbase. Originally, AI could not accept a 5 GB TM + large termbase + your file for translation in one request.
With the fine-tuning feature, you can pre-train the model with your translation assets, such as TM and glossary no matter how big your localization assets are.
However, I will ask our devs if there is any workaround to use the smaller % match for approval.
Our developers want to ask for some more information.
Can you please share the info on how exactly you fine-tuned the AI, what do you mean under ‘AI automatically confirms translations’?
Also, which way do you translate the files, pre-translation via AI or MT?
Please share as many details as possible.
Looking forward to your reply!
I fine-tuned the AI using the translation memory texts I uploaded.
It was a script consisting of about 10 Turkish sentences and 10 English sentences.
This text was for a test run.
I then opened a translation project using the same languages.
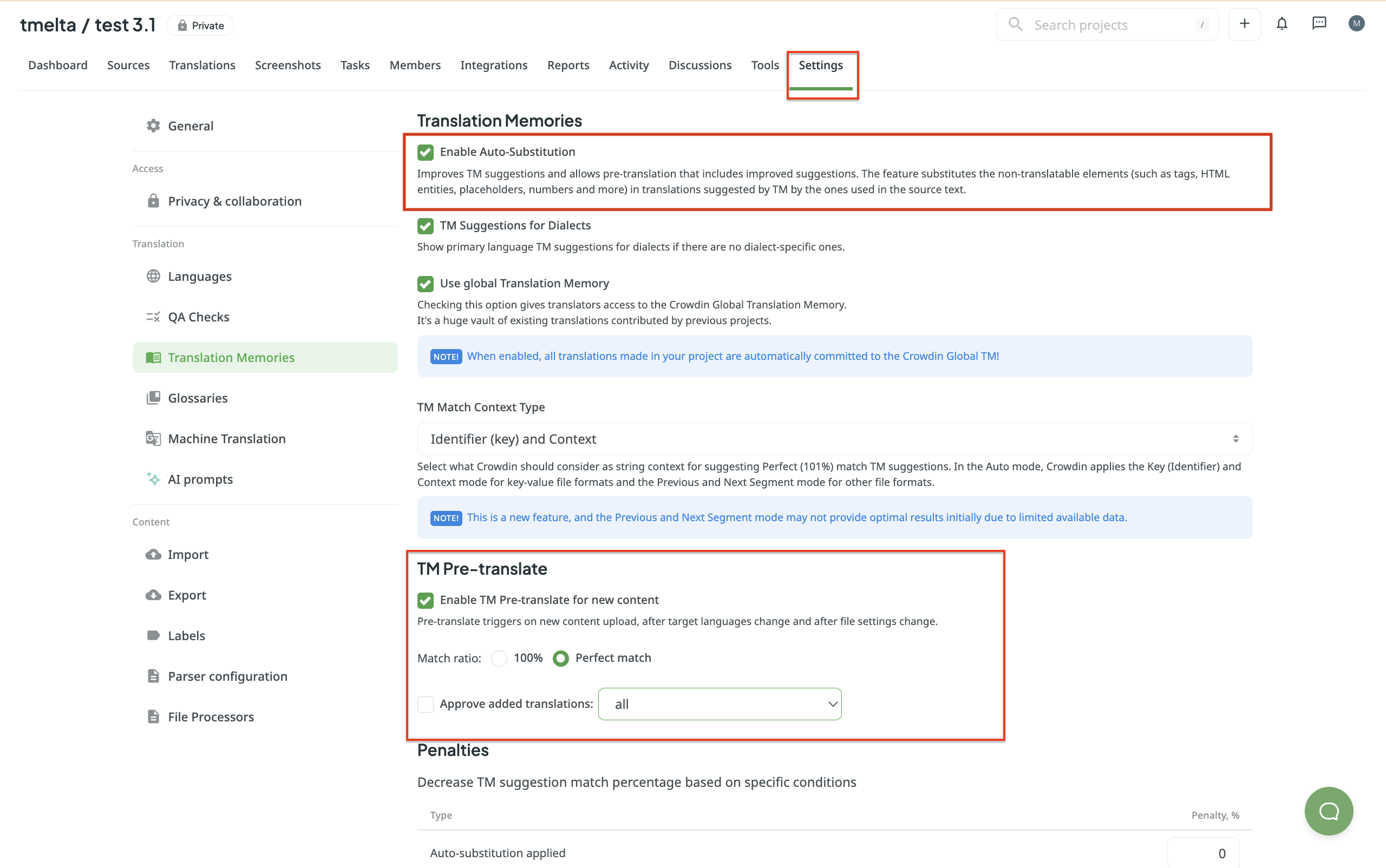
To see the effectiveness of the AI’s fine-tuning option, I uploaded a Turkish text that was %50 similar to the one I’d uploaded to the translation memory.
I then clicked on the Pre-translate with AI option.
Since the text I’ve uploaded and the text in the translation memory are %50 the same, I expected the AI to automatically approve the words that match the translation memory. I mean, I expected that even if the matches are %15 percent, it should approve those words during the pre-translation process.
What I want in the fine-tuning option is this;
Let’s say I have previously translated the word ‘‘arttırmak’’ as ‘‘increasing’’ from Turkish to English, and the AI has saved this change for the next texts.
After that, whenever I upload a sentence containing the word ‘‘arttırmak’’, I want the AI to always pre-translate it as ‘‘increasing’’, even if the rest of the sentence doesn’t match the TM.
Is there a way to do that?
Hi @Dima @Ira @Tania @Natalia @DianaO ,
I am also having the same problem, how to set up AI to suggest translations with words it can find in TM?
For example:
String that I have already translated:
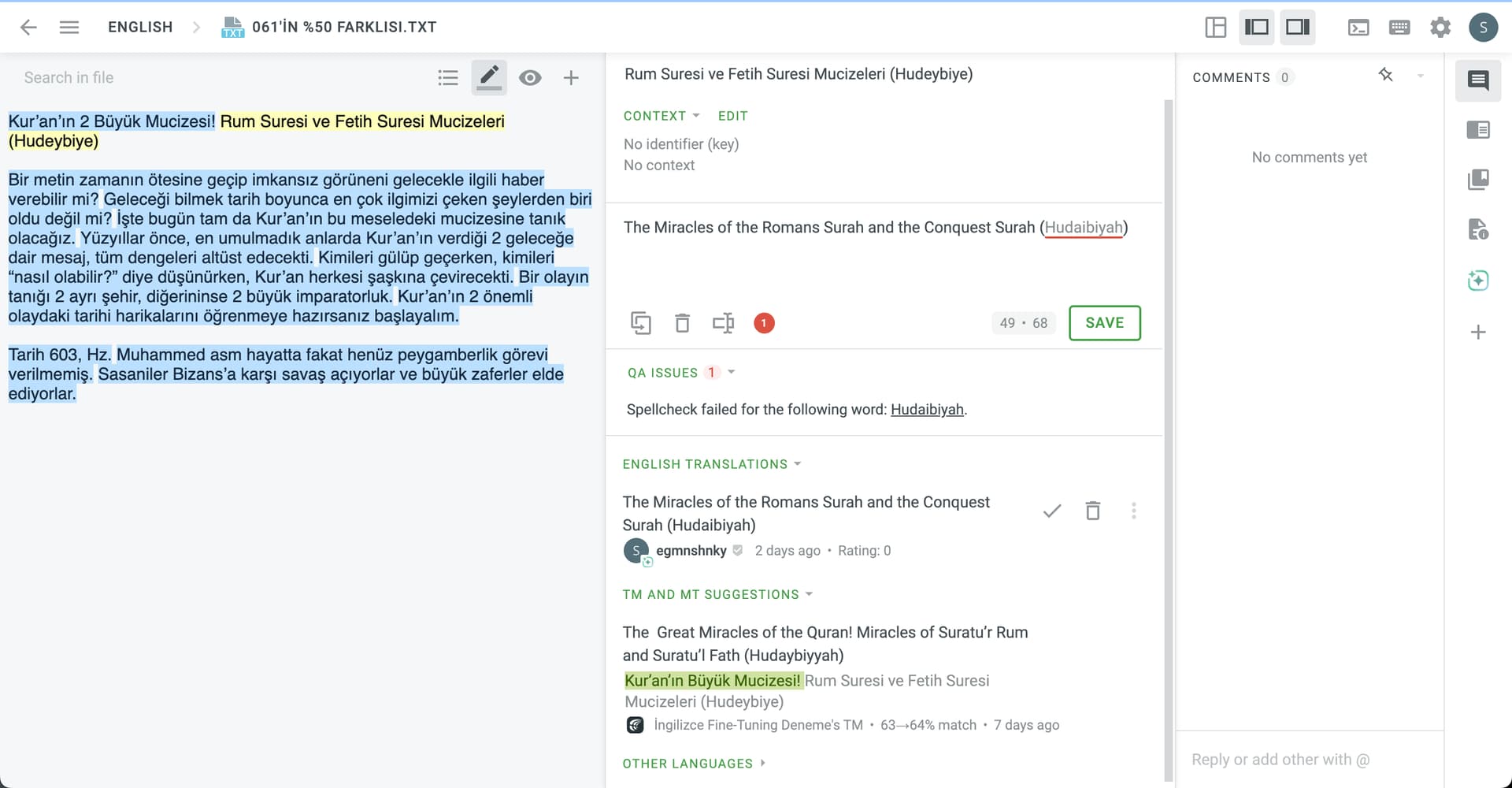
Key 7F38901F :⠀Shiny
Translations :⠀Nguyệt quang sứ
String that has not been translated but this string contains a word that I have translated before and need AI to suggest the correct word that I have translated before:
Key CC69B96A :⠀Glaze: Shiny
Translations :“something that AI will suggest”: Nguyệt quang sứ
__________________________________________________
My project name is: The Sims 4 Việt Hóa - P4
Project ID is: 761117
Thank you guys in advance ![]()
Hi Tom,
You’re welcome to switch the AI pre-translate prompt mode to the Advanced > specify to use translation memory matches > and set the Translation memory matches:
%tm%
Hi @Natalia ,
The thing is, I did try before asking, but it didn’t work. No matter how I set the prompt, the AI still doesn’t suggest the word ‘Shiny’ as it should, like the way I had translated it. It keeps suggesting the common, literal meaning of the word instead of the contextual meaning I used in my translation. I’m not sure if the issue is that the TM considers the match between the string ‘Shiny’ and ‘Glaze: Shiny’ too different. When I tried lowering the minimum match threshold for TM suggestions to 40%, I still couldn’t see the string ‘Shiny’ appear. So could that be the reason why the AI also fails to suggest the correct contextual translation of ‘Shiny’ that I had already translated?
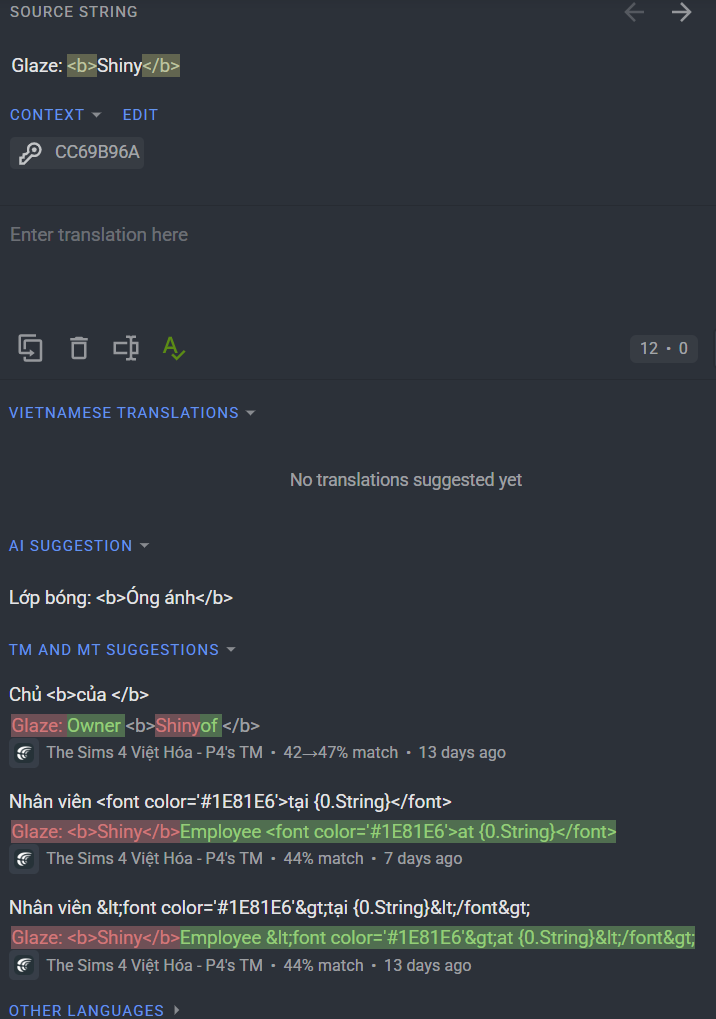
Dear Tom, you need to have exactly same string in TM too, it’s a small match (42%), so that’s why it can work as you see it now
Hi @Natalia ,
I’m sorry… but I don’t understand… ![]()
Like… what exactly should I do now? No matter if I set the TM to the lowest minimum match, or keep it at the default, or give the AI detailed instructions in the prompt, it still doesn’t suggest the correct translation for ‘Shiny’ in the sentence of other string
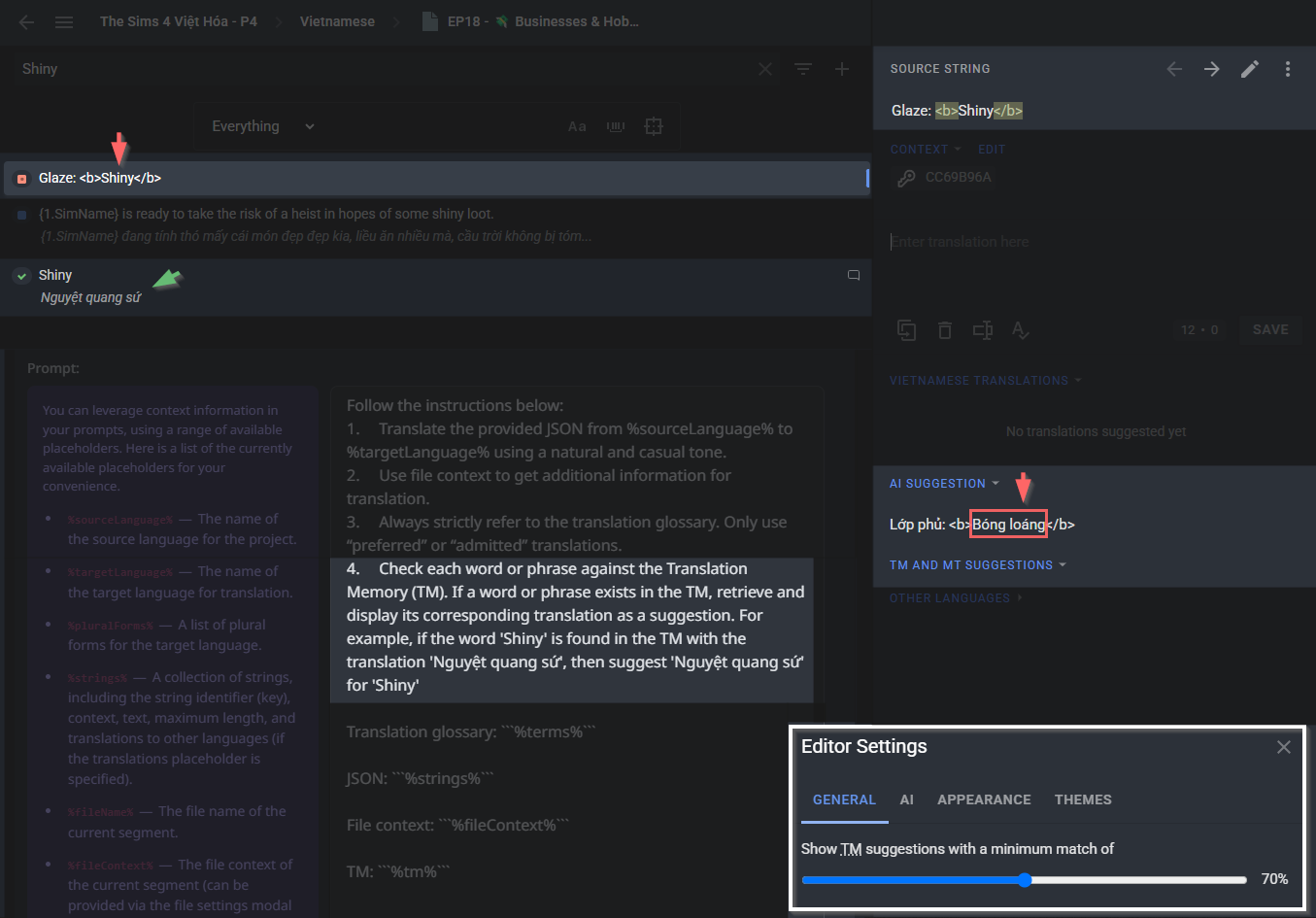
Hi @lhqt0703 the thing is that you have that word within a different string. The AI takes into consideration the tm matches but in case there’s the same string in the tm already. Let’s say you have
key1:Apple
translated to Swedish as
Key1: eple (not correct translation)
so this record is in your TM and when translation via AI, the ai would by default add the translation äpple but since you already have this string translated in the project, the AI will take that into account.
While in your case you translate Shiny and in your TM you don’t have this record, you have Glaze:<b>Shiny<b> which is different and the similarity is not enough to consider that translation
in the AI prompt you may specify an extra point something like Translate Shiny as … to < specify language >