I tried to apply the md API to my Rmd files using GitHub sync.
But I found out that it is currently impossible to achieve this in Crowdin while keeping the original Rmd file format.
Therefore, I am trying to set custom segmentation for Rmd where the txt API is applied.
If anyone is considering a similar approach for translating Rmd files, I would appreciate any recommended settings. Thank you!
2 Likes
Hi @kozo.nishida ,
I see you contacted our team a day ago regarding .Rmd files and as a solution it was suggested to use File Type Modifier app
I’m afraid this is the only solution at the moment, sorry!
1 Like
Hi @Roman ,
In our projects (Bioconductor and The Carpentries),
we need to translate Rmd without modifying the file type.
Therefore, I had to give up on using File Type Modifier app.
Instead, I would like to upload an SRX file for Markdown to the segmentation app.
(I will apply it to the Rmd files [recognized as txt].)
If you know of an SRX for Markdown, could you share it in this community?
1 Like
Hi @kozo.nishida ! You are welcome to take a look at the articles attached, where it is described how to set up the segmentation rules:
1 Like
Hi, I’m working with @kozo.nishida on this project.
I have some clarifications to make – I think we may actually be able to use the File Type Modifier app, but we need some help.
I have successfully set it up to import .Rmd files as .Rmd.md with these settings:
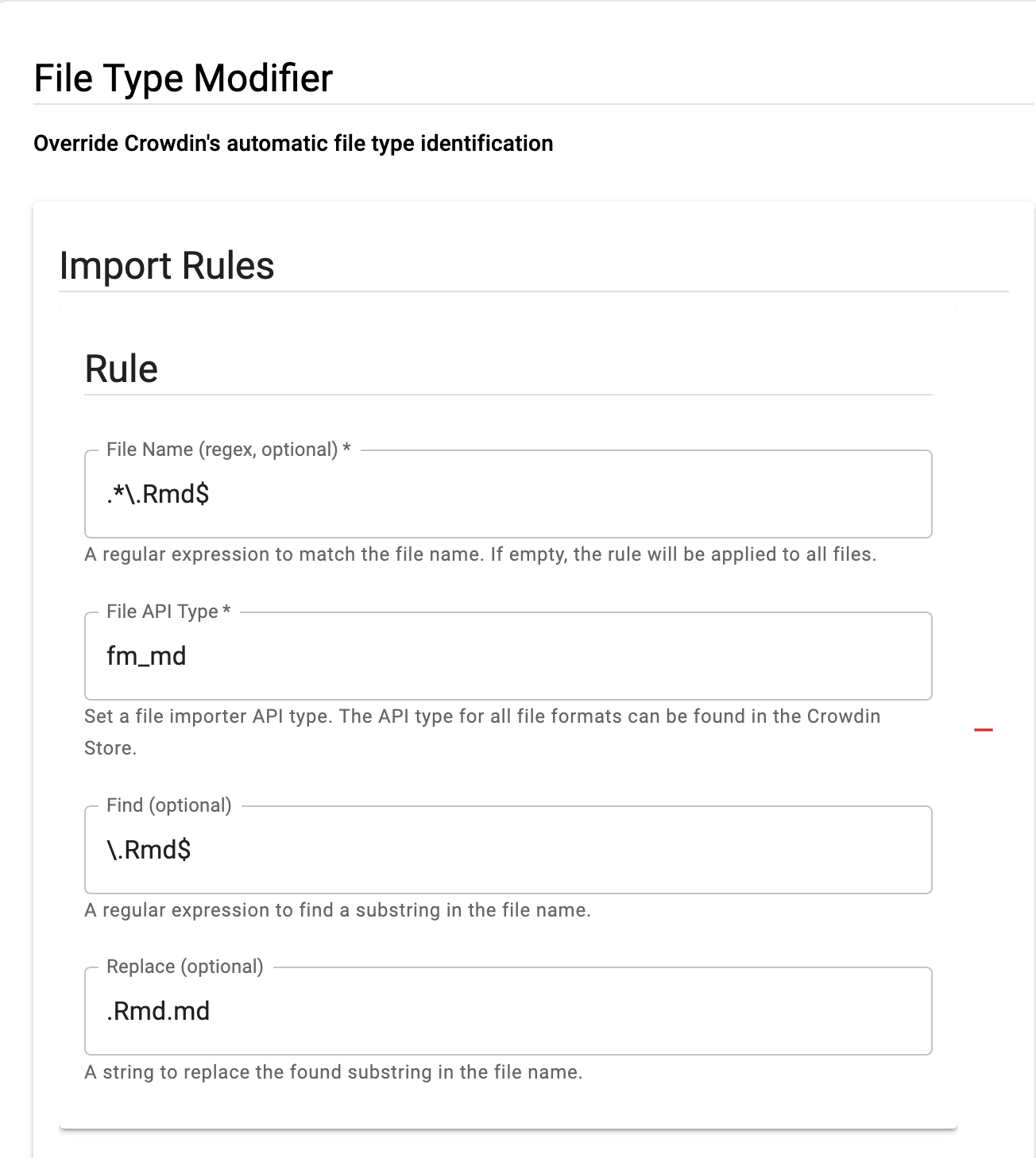
These files then get parsed as .md in the editor, as desired.
(Aside: Why I am limited to one image and two links? It makes it difficult to communicate what we need help with, which seems rather counterproductive).
1 Like
(Continuing a new message, so I can post more images and links ![]() )
)
The problem is exporting the translated file back out (we need to change it back to .Rmd for our project). We are using GitHub integrations. I have set up the Regex Content Processor tool to change the .Rmd.md file to .Rmd like this:
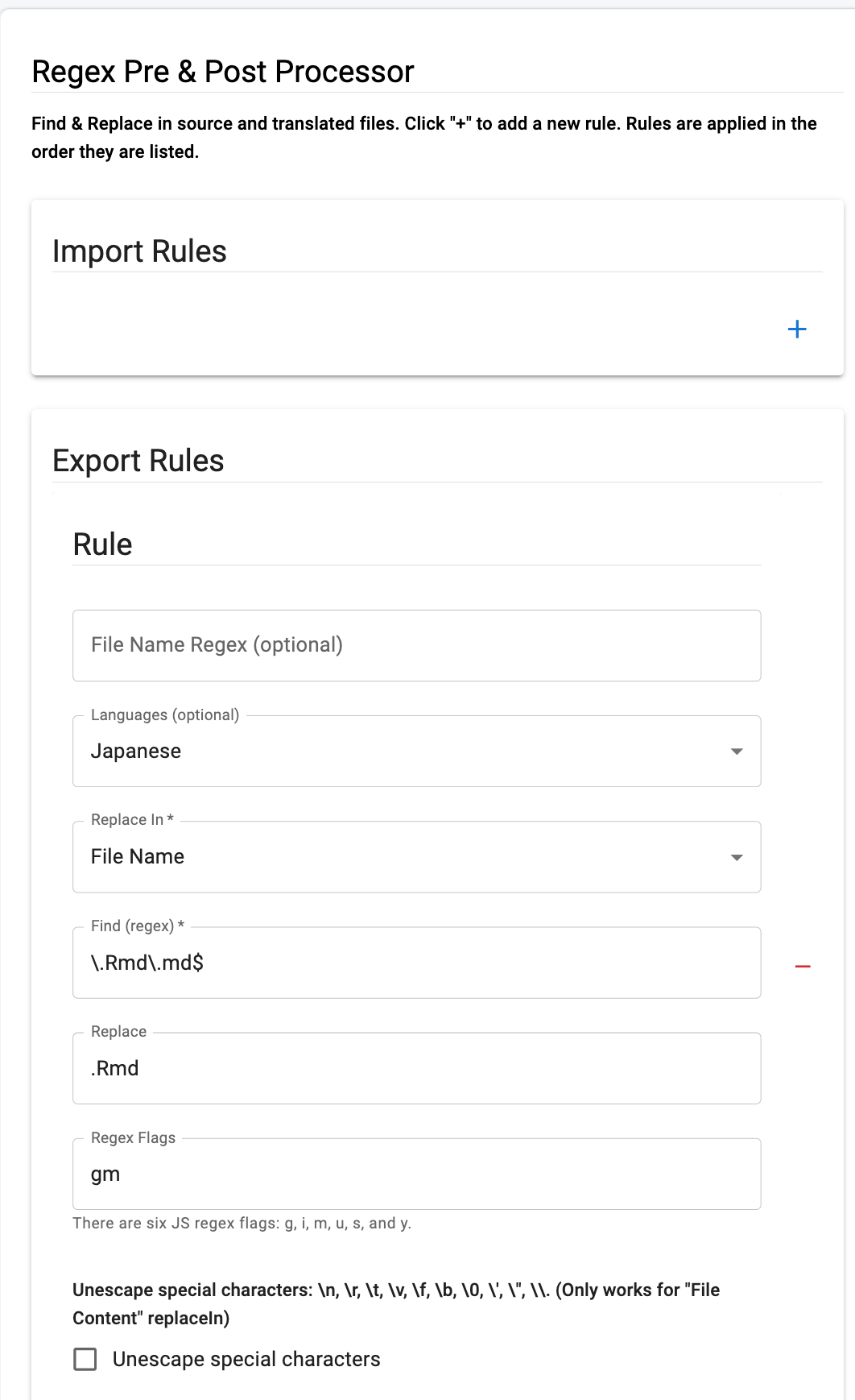
1 Like
However, the problem we have now is that the translated file does not show up at all in our GitHub repo (https://github.com/joelnitta/targets-workshop/tree/l10n_main/ja). We have configured it so that translations should appear in the folder %two_letters_code%/episodes/%original_file_name%
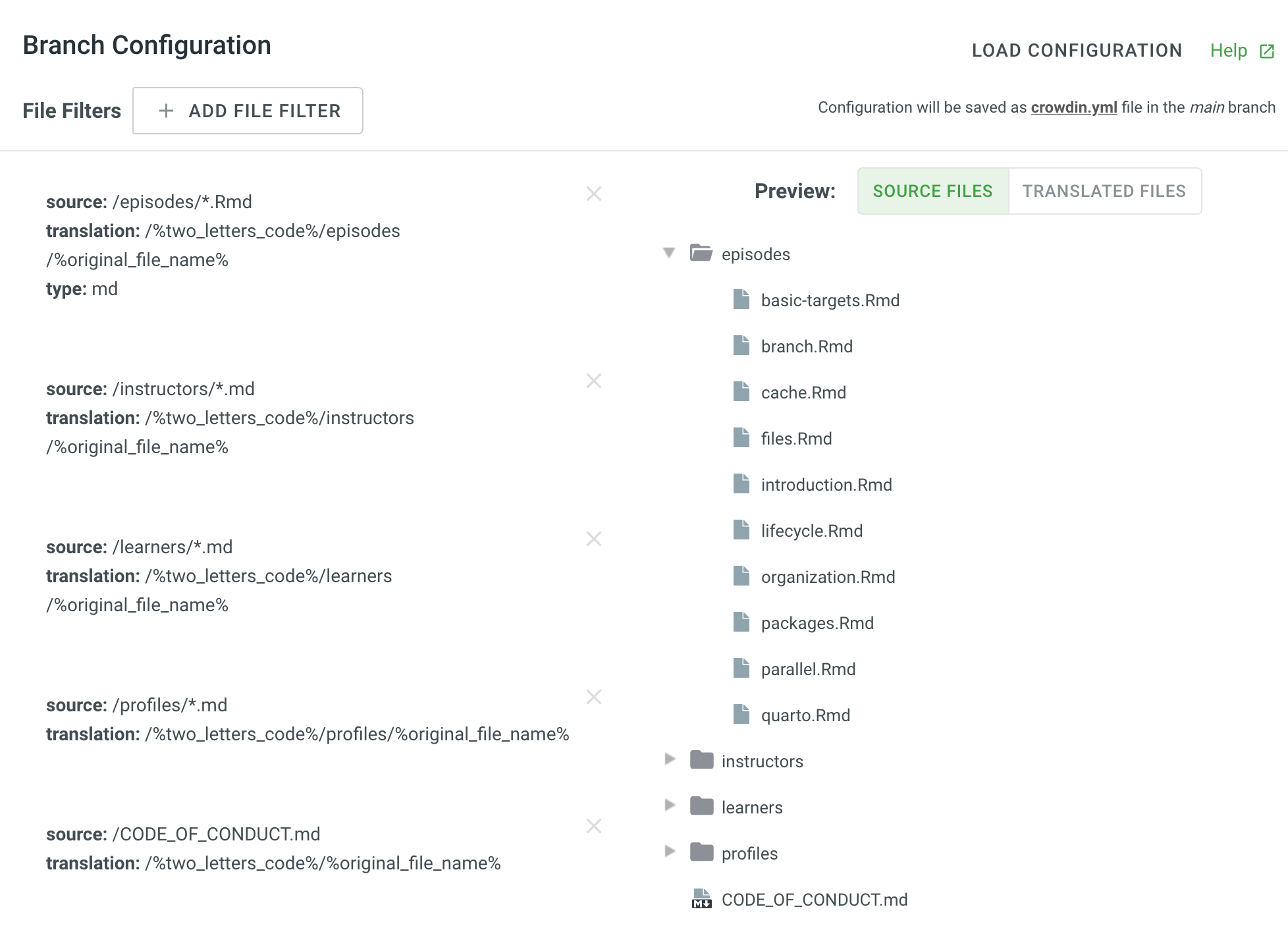
… but the episodes/ folder is completely missing if you look at https://github.com/joelnitta/targets-workshop/tree/l10n_main/ja
Any suggestions for this workflow would be greatly appreciated. Thanks!
1 Like
Hi @joelnitta ! As far as I can see, the preview is opened for the source files. Could you please share the screenshot of the preview for the translated files?
1 Like
Hi @Tania
I tried applying the ‘typical SRX file’ from that article to our
, but it seemed not to consolidate multi-line sentences into a single segmentation.
I also think that the rules generated by the rule generator are very limited.
Could you provide more examples of SRX, not just Custom Segmentation | Crowdin Documentation ?
Ideally, I would like an SRX that performs segmentation in the same way as the md API to be shared within the community.
1 Like
Dear @joelnitta ! Please contact us via support@crowdin.com. We will be glad to provide you further assistance there ![]()
2 Likes