Hi all. We’re currently running into the following issue. As a source, we use an XLIFF file that’s generated in Paligo. It appears that sometimes the tags, which contain a unique ID, that are contained in its segments change.
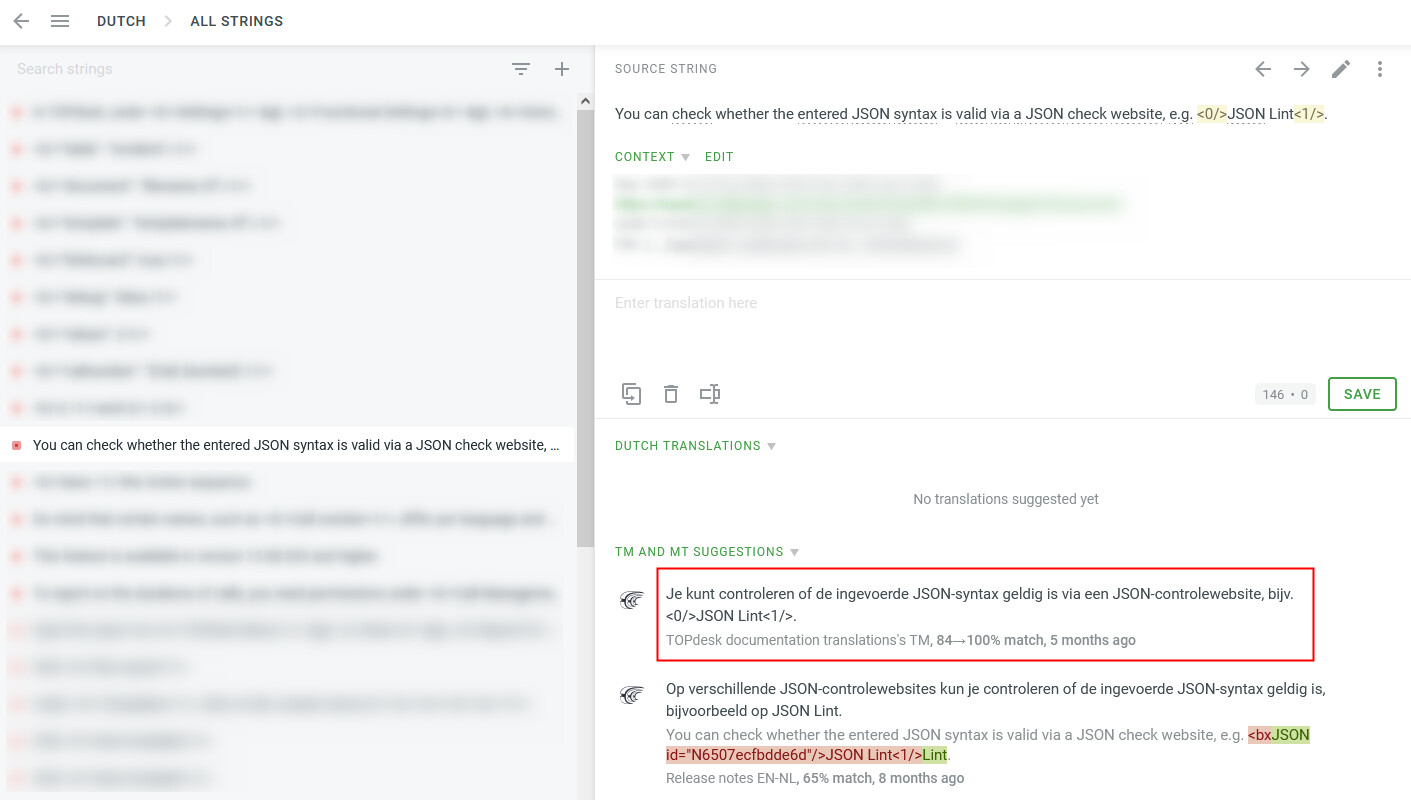
When I open the strings that don’t get translated by the pre-translation feature in the editor, I very often see a suggestion appear that originally isn’t 100%, but becomes 100% after applying that auto-substitution. However, I wonder why a lot of these segments still don’t get translated by the pre-translation. It does successfully apply it for a significant amount of segments, so I’d expect it to work.
It’s becoming quite a big problem for us, because we don’t want our translators to walk through all those segments again. 1) they basically already translated them, 2) it’s a lot of work to go through them one by one.
Anybody who recognizes this issue? Any ideas of how to approach this?
Hi Olenka. I just ran the pre-translation again. Surprisingly it managed to translate a couple of new strings. But still not all of them. The screenshot I added shows one example of a string that isn’t translated, although through auto-substitution it shows a 100% match.
Dear Tim,
Thank you for the video recording, we’ve checked everything once again and we are already familiar with such a behavior. We have a task for the technical team to solve it and pushed them to speed up