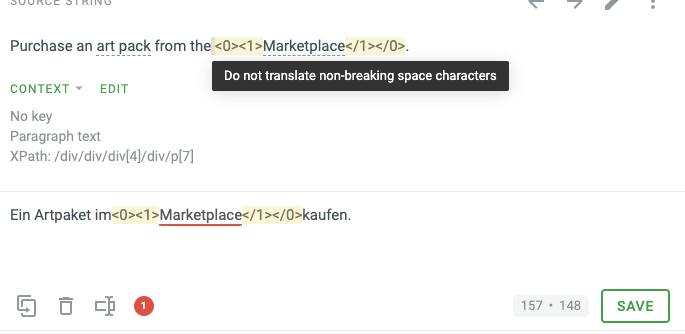
When I use either DeepL or ChatGPT 4.0 as pre-translation step, I encounter the issue, that space characters in the output texts are missing. See screenshot:
It seems there is no general setting in Crowdin which allows any MT to consider “translating” non-breaking spaces. Words encapsulated within tags are missing spaces to words before and after the encapsulation.
I tried to add a prompt for ChatGPT:
Please ensure that a space character is added before and after HTML markups in the output text to separate words, no space characters should be added if the HTML markup is at the beginning or end of a sentence;
But this prompt did not help either.
Any suggestion which helps me to auto-solve this issue and not having to proofread all content and add spaces manually?
MS Word file, English source, Italian as a target, and with our application that also uses GPT, and as a result both tags and non-breaking spaces were preserved.
Some engines may not support specific language pairs. There are also cases when a whole string is not “visible” to MT because of the amount of tags inside.
So in general, it’s always recommended to use Proofread after the MT pre-translation to make sure you receive the highest quality suggestions.
I contacted you directly to review your inquiry in more detail.
thank you for the quick reply. It seems your direct email never got through.
I have the issue especially with translating Zendesk articles. 70-80% of the time, the translated text ends up being missing non-breaking spaces in the translated strings. See the above example.
And solving this issue, would greatly save time when the KB has 200+ articles
I’ve sent messages to both team-shared email and your personal one, please double-check from your end, maybe you missed the notification or they went into spam.
We test all our integrations before adding them to the platform, all of them are fully functional.
We use API connection with all MT engines (DeepL, GPT, Amazon, etc). When MT is connected, we’re just like a “bridge”. Our system doesn’t affect the MT suggestions or somehow modify them, therefore in most cases this can’t be somehow solved or changed from our side.
I understand that proofreading may take additional time, but this is the best solution in this case.