Also tried just using https://docs.lizardbyte.dev/en/latest as the main url.
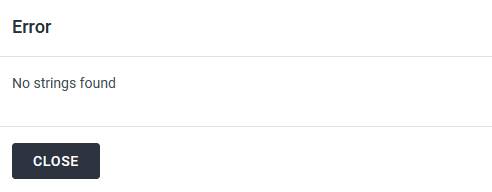
Either way, I get “no strings found” when importing the site.
I have a feeling it is something to do with where the page is hosted (readthedocs), although I previously attempted to import a site there and it worked in a different crowdin project.
Logs are empty, so I’m not sure how to diagnose this.
It is good to hear that the site is imported without errors if you do not specify the ignore_by_css_classes: crowdin-ignore parameter in the configuration. Maybe the path of the page in the ignore was specified incorrectly
When you try without parameters include or exclude paths, do you get an error every time? For example, the first time you may get an error, but when you try to import the site again - everything goes successfully
@Roman it’s a CSS class, not a path so that doesn’t make much sense.
If I re-add the CSS class to the ignore field, it will error again. It is only working when the ignore class is empty.
There are around 150k strings in this project, many of which probably do not need to be translated as they are code blocks. Note, I currently do not have the CSS class in the html, although I wouldn’t think it would fail to find any strings due to that. It also fails to find anything when scanning the very first page, and does not even attempt to scan the other pages where the CSS class could potentially exist.
Sorry for the late reply! We have made some fixes from our side and now everything should work fine even with the ignore_by_css_classes included in your snippet. Could you please give it a try and let us know how it works?