If it’s a Github integration I’d suggest just copying all files in the new branch, and editing the integration (i.e. connecting the new branch, so you have 2 in total, old and new). The new files will be uploaded with the new branch, and the old ones can be safely deleted.
I think you are you are suggesting that I create a new branch in git then update the integration to point to that, then it sync.
So if I want to keep my original branch (which I do, because it is main), I might then repeat the process - re-sync main which will copy the strings across, then delete my branch?
But I already started doing the manual process of renaming, updating, deleting as per the original suggestion. Will this have broken my integration?
During the export we re-build the file, so technically this can happen. I assume &check is not the only way to “show” a check mark (at least, depending on the tool/system), and this can be solved with a few strings of code (this app can replace content after file export but before translation download)
Its a problem because it changed - this all worked fine in original import. I’ll try substitute something like
So if I want to keep my original branch (which I do, because it is main), I might then repeat the process - re-sync main which will copy the strings across, then delete my branch?
It would be enough just to add news files as a copy, so you have both old and new sources in 1 branch. They can be in a subfolder, etc
Its a problem because it changed - this all worked fine in original import. I’ll try substitute something like
Perhaps due to a change of the parser version the check mark recognition also changed - please try replacing it and let us know how it goes
All actions that will result in a “new file upload” will work. It’s just a thing of preference.
If you just rename the file_1 to file_111, this will not change the parser version because it’s defined when the file is imported for the 1st time into the platform.
You’ve mentioned that the remaining and deleting processes have broken the integration - do you see any synch errors or conflicts in Github?
Anyway, all new source file uploads will work, so the system just detects that this is a “brand new” source file, not the renamed or moved somewhere old version.
The process we recommend by default is next:
You added branch_1 with new files inside
Users translated it
You activate the duplicate sharing option
You add branch_2 with new files inside
Duplicates activate, so files become translated (translation migrates from master strings)
You safely delete branch_1, once its deleted strings in branch_2 become master strings
This process keeps the authority of translation, the history of translation. I hope it shouldn’t be an issue just to swap branches in GitHub integration.
As for the 2nd option, you can always run Translation memory pre-translation - this would apply translation to the strings. It can be used with both Perfect (string + key) or 100% match, but in terms of authority to these suggestions would be considered as you added them.
I’m starting some of this, still manually and spotting some differences.
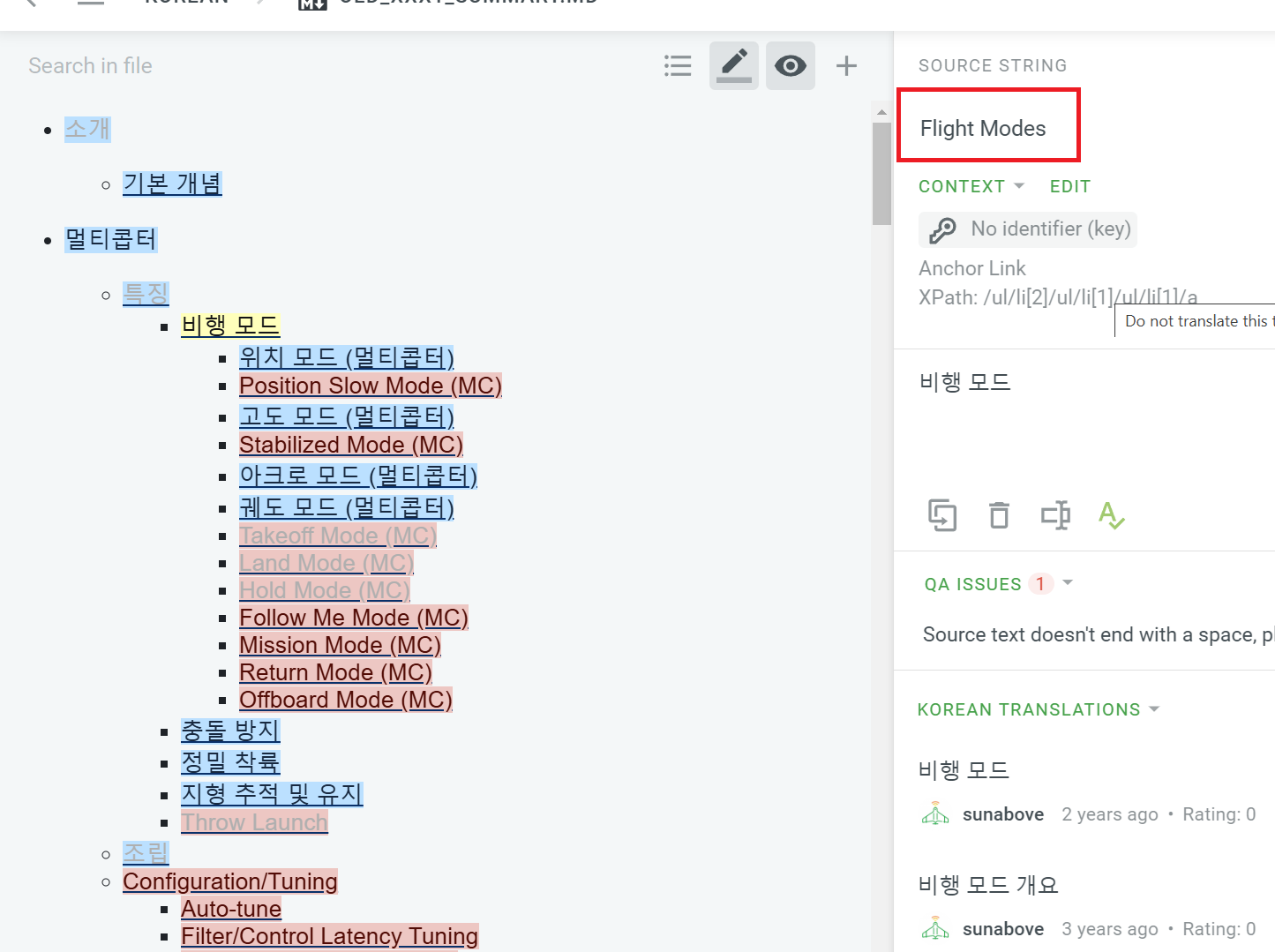
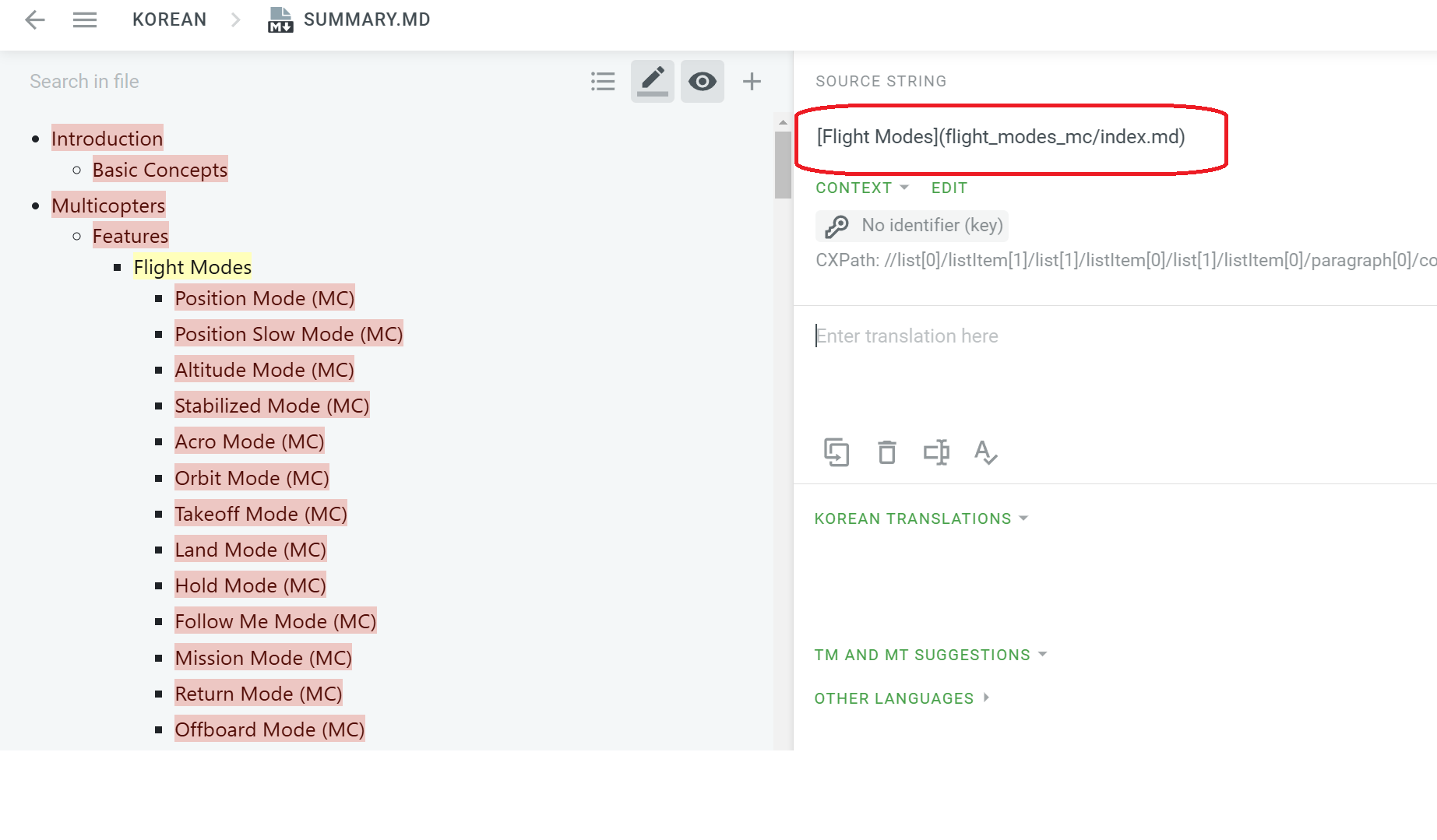
Specifically, links are now offered as the string [Introduction](index.md), whereas previously the string offered for translation was Introduction.
It breaks a lot of translations because the strings aren’t the same, obviously. Worse, I worry that someone will try and translate index.md in the link, which they should not.
We will be much appreciated if you could share with us all the steps that have already been taken from your side. Also please share with us some examples of the issue you described in your last email.
rename a small number of docs to old_<original name>.md
import the original source doc again - in this case using the UI, but I have tried with an uploader script with same result.
Deleted the old_Xxx doc.
I’ve inspected a small number of docs - to see what is displayed in the translation UI.
This is how I know about the markdown link import being different.
I haven’t imported everything yet, because it is important I understand what this new import does in order to understand how much it will break existing translations. For example, the markdown link issue means that there are no longer any translation matches on any topics in the sidebar of my site - that’s more than 500 topics per translation.
I also haven’t followed the suggestion to manage the update via git integration. I don’t fully understand the steps and it looks risker that just scripting the update.
Does that explain clearly where I am at?
Thanks so much to all of you for being so responsive. I can certainly update to the new approach now, just not sure of what the churn will be, and how to best support the translators so that their information isn’t lost.
When you are re-uploading the file to the project and using the duplicate option to migrate the translation, then the translation history of the strings will not be preserved once you remove the old file from the project. In the newly uploaded file with the migrated translations there will be a record that translations migrated from the master. Please kindly take a look at the attached screenshot:
Thanks. I’m OK with losing the translation history, but the my problem is that the translations do not ALL migrate. That can be observed in the UI.
Specifically I have posted two images of my sidebar below. The first shows the original, and the second the new imported version. As you can see none crowdin is now identifying the source string as the whole markdown link, and not just the display string. That means that it looks like a different string to crowdin, and is not being migrated for every imported string that happens to have a link.
Hi!
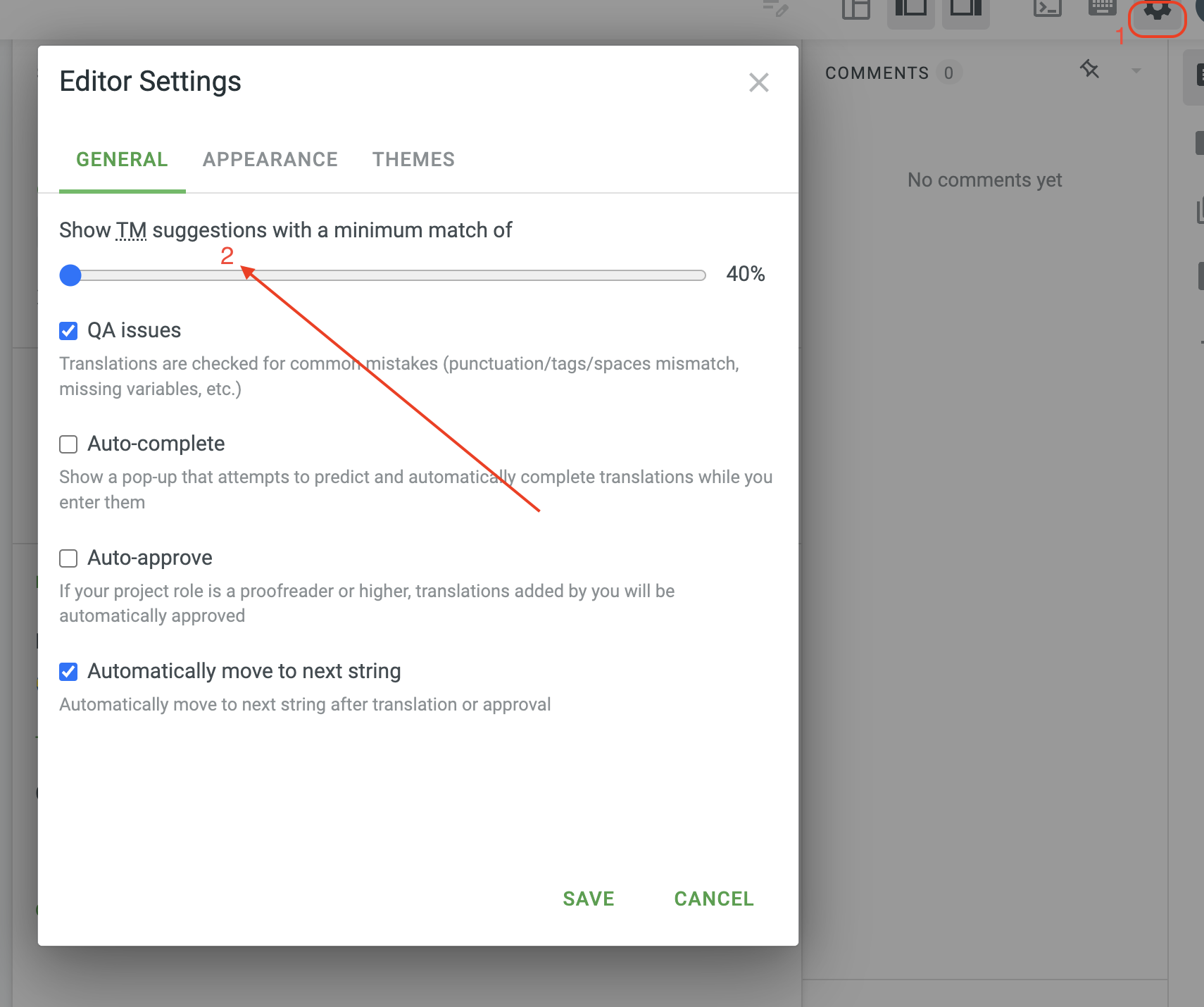
You can try changing the TM suggestion percentage match to a lower position and then manually add translations to strings where translations are not applied automatically