Hi everyone,
A few days ago we noticed that new Markdown files uploaded to our Crowdin project no longer had context automatically assigned to the strings.
Did something change in that flow, or are we missing something?
Hi everyone,
A few days ago we noticed that new Markdown files uploaded to our Crowdin project no longer had context automatically assigned to the strings.
Did something change in that flow, or are we missing something?
For example, this context was auto-generated on Crowdin when the file was uploaded:
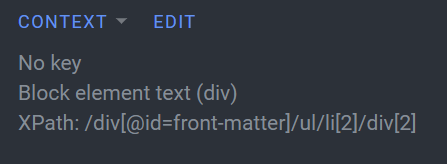
But uploading a new file leaves context as “No context”, returning null in the API.
Hi,
Recently we released support for a new version of the MD file format. The recent update to this format may have caused some segments to be parsed differently. We are currently working on the release note for this update indeed.
Is there any way to get the auto-generated context on segments now?
We have entire files that have 0 string-based context which is breaking our workflows.
@nhcarrigan Would you be able to send an example of the file you’re currently using to support@crowdin.com? Additionally, we’re interested in gaining more insights into how this issue is specifically affecting your workflow. This information will be valuable for us to collaborate with our technical team and find a tailored solution for you.
No followup on this yet?
My markdown files are getting still getting no Context and no formatting tags (links, bold, etc).
Old processed file
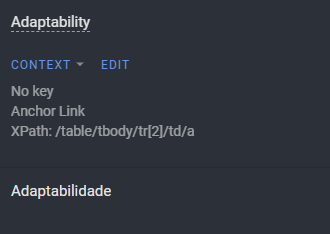
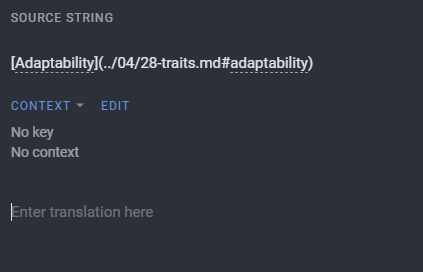
Recent upload of the same file:
Hi @luizbgomide,
Sorry for the delay in reply! Our team was on the Christmas holidays ![]()
The task on the matter to improve the context of the new version of .md file has already been created to our devs. We will get back to you immediately once it is done.
@Olena thanks for the reply. I was just complementing the information on mentioning that the tags were also not being detected properly.
@Olena any news regarding the Markdown processing? It still isn’t working properly.
We are still working on the Markdown processing issue. We will notify you with an update as soon as we have one.
I’m sorry to keep bringing this subject but the Markdown processing is still broken after at least four months.
There is no context, no tags, no links, the strings are shown as pure text. If this issue cannot be solved, I urge that you revert to the previous Markdown version that was working just fine.
We understand the importance of having a fully functional Markdown processor.
Could you please provide the following information to address the issue better to support@crowdin.com?
This information will be crucial for our technical team to investigate and resolve the issue as quickly as possible.
I would also ask that you revert to the previous processor, or at least allow us to change our settings to do so.
This was clearly broken several months ago.
Hi Andrew, our team told us that we don’t have Xpath as the document is handled as the text document. There is also no indication of the type (anchor link), since now the fact of the link is visible in the text of the source string itself, compared to the fact that previously the title and URL were translated separately
We’va already answered your e-mail where we asked for the examples of the context you’d like to see and the examples of the strings
Hey y’all, I was able to get my files parsing correctly by setting the type to md35 in our upload configs for standard markdown files, and fm_md for files with frontmatter.
Hello @nhcarrigan!
It’s great that you were able to resolve this, thank you for telling us ![]()
The default parser for Markdown still has all the issues after one year. I can “avoid” the issues by uploading files via Github integration and setting the type: md35, how can I do the same for files uploaded from the Sources page?
Also, is there a timeframe for this to be resolved?
You can specify file type: md35 if performing the upload directly into the Source tab. But you need to use the CLI to complete this task. If you upload files via UI, by drag-n-drop from your PC or laptop, this won’t work, as with UI upload you can’t indicate file type.
We’ve made a lot of fixes/feature requests within a year, so now Markdown files should be parsed better, and overall user experience with this file format has been improved as well.
If you still experience some issues, please provide the following information to support@crowdin.com:
I think you meant that you can’t specify it, right? I’m replying the e-mail with the solicited information.
BTW: Is there a way for me to get a list of available parsers? For example, I know that md35 works, but I don’t know what else is available.