I’m a translator working on some projects here. My manager often delete source strings, add minor changes and upload them as new ones. In most cases, the Translation Memory picks up some translations on the past strings, but not always. When the source string is very long, translations are often missing: no TM Suggestions are shown. Is there any way for translators to recover past translations on deleted strings?
Hi!
If the string was previously translated > then deleted > and added again, you’ll see suggestions from TM in the editor. But in case the string is completely new or was modified there won’t be suggestion.
Also, in the Editor settings it is possible to change the percentage of minimum match ratio shown to you, please see my screenshot below:
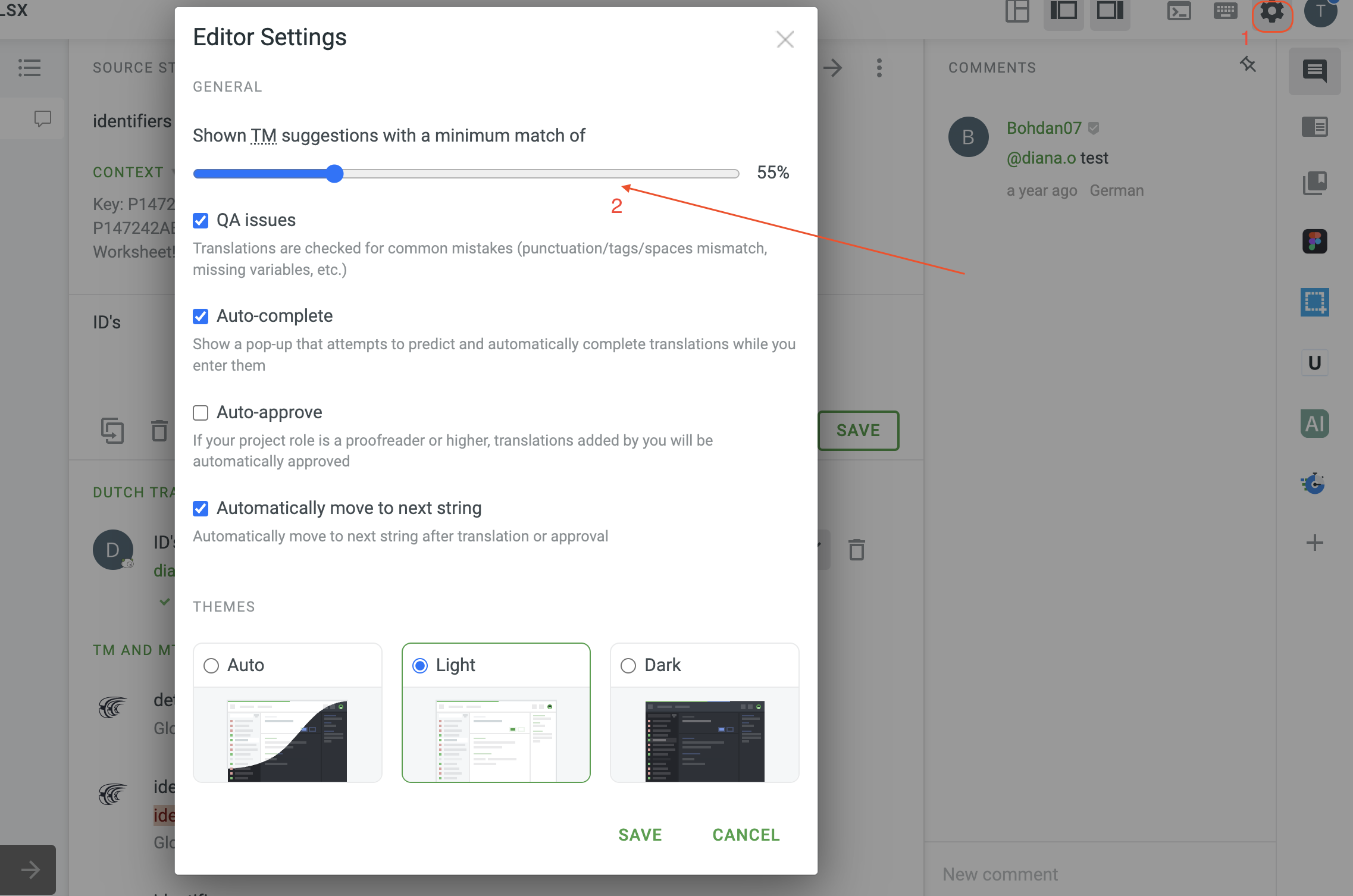
Thanks for quick reply, but the percentage setting does not matter because the revised strings are at least 80% identical to deleted ones. This disappearance of past translations occur when the string is about 1400 letters (in English) or more.
How does the TM work, can it handle very long strings properly? I think there is room for improvement in Crowdin’s TM algorithms. A simple solution is automatically dividing long strings into several parts of manageable size (say 1000 letters at most) and treat them as separate entries in the Memory.
Hello,
Crowdin handles string segmentation according to the default rules, or custom segmentation rules that can be set. So the string is uploaded how it is expected in the source file configuration. Here you can take a look at the article about Custom Segmentation.
It may be better to segment very long strings, to prevent such occurrences - when the TM record is not recognized.
I have read the linked article. I will request my managers to segment the source into smaller parts. Thank you.
PS: I just tried “Open Command Pallette > Search TM” for the first time and found past translations in the Memory ! So the Memory itself is fine, the problem is with your algorithm to show “TM Suggestions”.
Hi @hnishy ,
Yeah, it’s best to split very long strings into multiple strings, so it’s a good idea to ask project managers to set up segmentation
All translations are stored exactly in TM and nothing is lost ![]() Will try to improve it
Will try to improve it