Thanks for pointing me in the right direction, @DianaO.
After making some changes to your models, I got a macOS .strings source file uploaded.
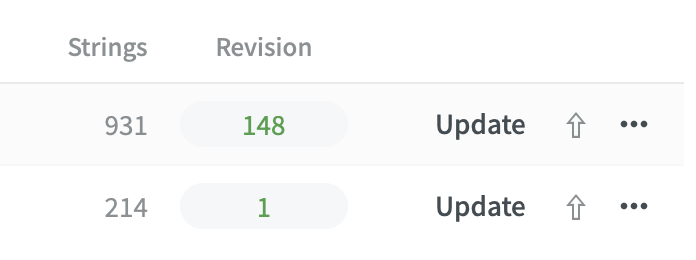
However, Crowdin doesn’t show it on the “Sources” tab as having the correct number of strings:
(In the screenshot below, the first line is for a file uploaded using the v1 API and the second line is for the same file uploaded using the v2 API using the script below. After uploading I downloaded both files from Crown.com and they are identical, so the files should have the same number of strings.)
The number of strings in the file uploaded using the v2 API has many fewer strings than the file uploaded using the v1 API. The number of words (shown by hovering over the number of strings) is also much lower. When using …View Strings, many of the strings are dimmed.
Below is the code I used for uploading, after making the following changes from @DianaO’s models:
- The endpoint is “storages”, not “storage”.
- I added my personal access token after "
Bearer ".
- I used
--data-binary instead of -F because-F prepends the file with several lines of metadata (the name of the file, etc.).
- The
Content-Type and Crowdin-API-FileName headers are required by the Add Storage API.
- NOTE: I have also tried
Content-Types of text/plain and text/strings but they have the same problem.
##########
PROJECT_ID= <integer code extracted from the output of Crowdin's List Projects API>
CROWDIN_PERSONAL_ACCESS_TOKEN=<personal access token as described by @DianaO>
PATH_TO_FILE_TO_UPLOAD=...
PATH_TO_A_TEMPORARY_FILE=...
##########
FILE_NAME="$( basename "$PATH_TO_FILE_TO_UPLOAD" )"
URL_ENCODED_FILE_NAME ="$( perl -MURI::Escape -e 'print uri_escape($ARGV[0]);' "$FILE_NAME") "
curl -X POST "https://api.crowdin.com/api/v2/storages" \
-H "Authorization: Bearer $CROWDIN_PERSONAL_ACCESS_TOKEN" \
-H 'Content-Type: application/octet-stream' \
-H "Crowdin-API-FileName: $URL_ENCODED_FILE_NAME" \
--data-binary "@$PATH_TO_FILE_TO_UPLOAD" \
> "$PATH_TO_A_TEMPORARY_FILE"
ID ="$( grep --text \
--extended-regexp \
--only-matching \
--max-count=1 \
'"id":[^,]*,' "$PATH_TO_A_TEMPORARY_FILE" )"
if [ -z "$ID" ] ; then
echo "ERROR: Cannot find storage Id!"
echo "Response was '$( cat "$PATH_TO_A_TEMPORARY_FILE" )'"
exit 1
fi
ID="${ID:5}". # remove "id:" at start
STORAGE_ID ="${ID%?}" # remove "," at end
Here’s the code I used to add the file to the source files:
PAYLOAD="{
\"storageId\": $STORAGE_ID,
\"name\": \"$FILE_NAME\"
\"type\": \"macosx\"
}"
curl -X POST "https://api.crowdin.com/api/v2/projects/$PROJECT_ID/files" \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $CROWDIN_PERSONAL_ACCESS_TOKEN" \
--data-binary "$PAYLOAD" \
where STORAGE_ID, FILE_NAME, PROJECT_ID, and CROWDIN_PERSONAL_ACCESS_TOKEN are the same variables set in the above code for uploading.
Note that almost all error detection and handling has been removed from the above code for simplicity.