Thanks @Dima ![]() so far it’s working well!
so far it’s working well! ![]()
You’ve actually touched on an improvement I intend to make, once we’ve bumped up our CrowdIn subscription plan, to include custom workflows! ![]() I’d like to add an automated pre-translation step that uses both Translation Memory
I’d like to add an automated pre-translation step that uses both Translation Memory ![]() and the Machine Translation
and the Machine Translation ![]() engine to seed translations (as outlined in this support article) as soon as a change has been made on Figma and pushed up to CrowdIn.
engine to seed translations (as outlined in this support article) as soon as a change has been made on Figma and pushed up to CrowdIn. ![]() I can imagine that this will reduce the initial (manual) translation step of our localization workflow.
I can imagine that this will reduce the initial (manual) translation step of our localization workflow.
“From my database, I can see that you have English as both source and target language. Can you please clarify the need for it? Is it something you need for internal purposes?” - @Dima
This actually relates to something that had me a little unsure ![]() during the design of this localization workflow! I found that in the past, I needn’t add the source language to the list of target languages, because the source strings were all procured from the same repositories that the translations were getting sent through to. This was utilising the “Source and translation files mode” of VCS integration (GitHub), so branch configuration was pulling a resource file, with a full set of source strings in the source language (English). Then when the time came to sycnhronise translations back to the repositories, the target languages did not need to include English, since those source strings were already present in each repository.
during the design of this localization workflow! I found that in the past, I needn’t add the source language to the list of target languages, because the source strings were all procured from the same repositories that the translations were getting sent through to. This was utilising the “Source and translation files mode” of VCS integration (GitHub), so branch configuration was pulling a resource file, with a full set of source strings in the source language (English). Then when the time came to sycnhronise translations back to the repositories, the target languages did not need to include English, since those source strings were already present in each repository. ![]() (I hope that makes as much sense to you as it did in my head!
(I hope that makes as much sense to you as it did in my head! ![]() )
)
Now in the case of this new project’s localization workflow, the source strings are generated within Figma, from the copy present in design frames in that project. ![]() The idea here is that the designers can build UIs that contain strings, that can then be sent through to CrowdIn with unified key/identifier naming, and once translated, those strings can then be pushed through to the app repositories (Android and iOS) in the formats they require.
The idea here is that the designers can build UIs that contain strings, that can then be sent through to CrowdIn with unified key/identifier naming, and once translated, those strings can then be pushed through to the app repositories (Android and iOS) in the formats they require. ![]() The keys used in both codebases would remain uniformed, making things more manageable for the Engineering Teams
The keys used in both codebases would remain uniformed, making things more manageable for the Engineering Teams ![]() working on these projects.
working on these projects. ![]() Since the strings are sourced from Figma (in our case), the source strings are not present in the destination project repositories, so the source strings must be pushed through alongside the target language strings.
Since the strings are sourced from Figma (in our case), the source strings are not present in the destination project repositories, so the source strings must be pushed through alongside the target language strings. ![]()
This method of sourcing strings and generating required target bundles (inclusive of the source strings) is briefly mentioned in the following blog post:
This method seems to be required for use-cases where the source strings are procured from somewhere other than the place that the translated files are destined. I’d imagine most “Strings Vault” (.csv) workflows would require the source language to be included in the target languages list, particularly when the “Strings Vault” is created using a plugin (like the Figma plugin) or from within the CrowdIn “Source” UI, pictured below:
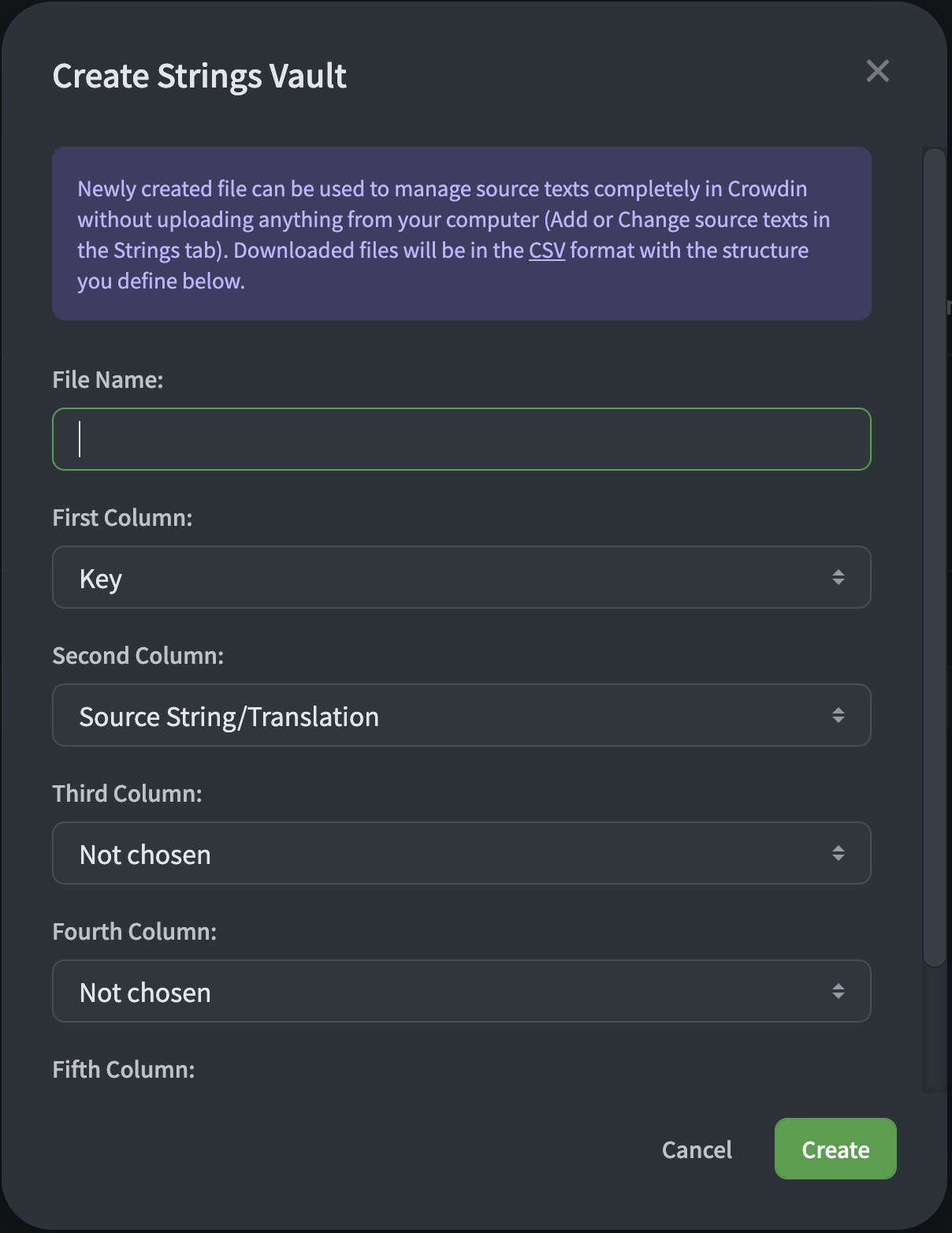
I hope all that makes sense! ![]() As always, I’m totally open to suggestions on ways to improve this workflow, though for the moment, I hope these walls of text can help guide those trying to achieve something similar!
As always, I’m totally open to suggestions on ways to improve this workflow, though for the moment, I hope these walls of text can help guide those trying to achieve something similar! ![]()